Almost a year ago, I set out to build and launch a SaaS product: FynCut. The goal was simple but ambitious—create an AI-powered platform that automatically cuts long podcasts and interviews into viral, vertical (9:16) clips ready for TikTok, Shorts, and Instagram Reels.
Technically, the product was a major success. It combined serverless GPUs, transcription models, active speaker detection, and automated video editing into a seamless background workflow.
However, operating a video-intensive SaaS solo is incredibly demanding, and after navigating the realities of infrastructure costs, bot blocks, and marketing, I decided to step back. Instead of letting the code collect dust on my hard drive, I am open-sourcing the entire project.
Here is the story of how FynCut was built, why it failed as a commercial business, and how you can use its codebase to build your own serverless AI video apps.
The Tech Stack: How FynCut Works
Building a system that processes gigabytes of video, transcribes audio, tracks speakers' faces, crops vertical coordinates, and burns styled subtitles requires a complex, multi-stage pipeline. Here is how FynCut handles it:
1. The Full-Stack Control Plane (Next.js & Inngest)
The client-facing app is built with Next.js 15 (App Router), Tailwind CSS v4, and Prisma ORM.
Because video processing takes minutes, standard HTTP requests will timeout. To solve this, I integrated Inngest for event-driven, serverless background queues.
- A user uploads a video via a presigned URL directly to AWS S3.
- The frontend triggers an Inngest event.
- Inngest coordinates the database state, makes secure HTTP calls to the GPU workers, handles automatic retries with exponential backoff, and dispatches transactional emails via Resend.
2. Scale-to-Zero Serverless GPU Engine (Modal)
Instead of renting a persistent GPU server (which costs hundreds of dollars a month even when idle), I built the entire backend on Modal.
- Audio Transcription: Runs WhisperX on an NVIDIA L40S GPU container to output word-by-word timestamp coordinates.
- Highlight Extraction: Feeds the transcript to Google Gemini using the
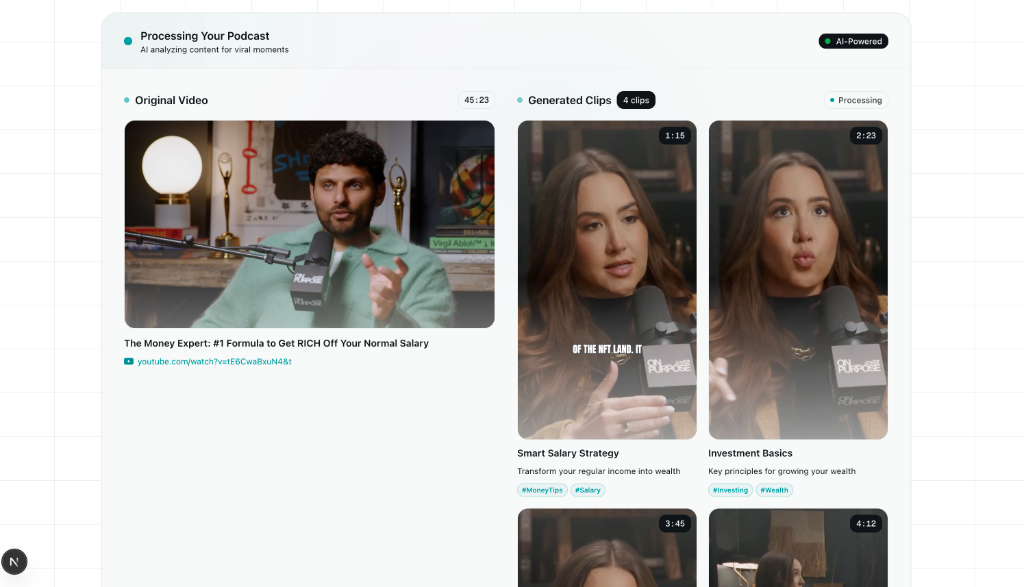
google-genaiSDK to find the most engaging hooks, viral segments, and interest scores. - Active Speaker Detection (Face Tracking): Implements the Columbia ASD face-tracking models in OpenCV and PyTorch. For each moment, it tracks who is speaking and reframes the camera dynamically from a horizontal widescreen (16:9) to a centered vertical (9:16) frame.
- Custom Subtitle Burner: A CPU-only container class that uses FFmpeg and pysubs2 to compile advanced styled subtitles (word-by-word active highlights, custom fonts, positioning) and burns them directly into the video.
Why It Failed as a SaaS
While the engineering was solid, running FynCut as a solo SaaS project hit several brick walls:
1. YouTube Bot Detection Blocks
Originally, the platform allowed users to paste a YouTube link, download the video via yt-dlp on the server, and process it. However, YouTube's aggressive bot-detection and IP blocking meant that downloading videos from serverless cloud IPs constantly failed or triggered recaptchas. I had to pivot to requiring manual S3 uploads, which introduced friction for the end-user.
2. Operating Costs & Margins
Video processing is incredibly compute-heavy. Running WhisperX, Active Speaker PyTorch models, and rendering HD video files takes considerable CPU/GPU time. Balancing user subscription prices against S3 egress fees, GPU cold starts, and API keys made the margins thin for a solo founder without venture capital.
3. Founder Burnout & Maintenance
Maintaining the active speaker detection model layers, handling FFmpeg alignment bugs, tracking down failing background jobs, and resolving payment gateways (Razorpay) while trying to handle marketing and customer support became too difficult to manage alone.
Why Open-Sourcing It Is the Best Next Step
Even though FynCut didn't succeed as a commercial SaaS, the codebase is a valuable resource. I am open-sourcing the frontend and backend so that other developers can learn from it, self-host it, or reuse the components:
- Serverless GPU Boilerplate: It is a production-tested example of how to link a Next.js frontend with a Python-based Modal GPU runtime.
- Automated Reframing Pipeline: The face-tracking and horizontal-to-vertical crop pipeline is a great reference for anyone working on computer vision and automated video editing.
- Styled Caption Burner: A complete implementation of dynamic subtitles using pysubs2 and FFmpeg with support for font styling and text alignment.
How to use this repository
The repository is split into:
/frontend: Next.js frontend with user registration, credit purchases, video progress queues, and a subtitle customization editor./server: Modal Python backend defining the GPU classes, WhisperX pipeline, and caption burner.
All setup, deployment, and configuration steps are detailed in the repository's README files.
Support & Contributions
If this codebase helps you build something cool, helps you learn serverless GPU programming, or if you just appreciate honest post-mortems:
- Give the repository a Star on GitHub: iyashjayesh/FynCut
- Submit Pull Requests to fix bugs, optimize speaker tracking, or add new caption styles.
- Share the project with other developers!
Let's build cool things together.